9月24日的2025云栖大会上,阿里开源新一代视觉理解模型Qwen3-VL。该模型在视觉感知和多模态推理方面实现重大突破,在32项核心能力测评中超过Gemini2.5-Pro和GPT-5。同时,Qwen3-VL大幅提升了视觉Agent、视觉编程和空间感知等关键能力,不但可调用抠图、搜索等工具完成“带图推理”,也可以凭借一张设计草图或一段小游戏视频直接“视觉编程”,“所见即所得”地复刻图表、网页和复杂程序。
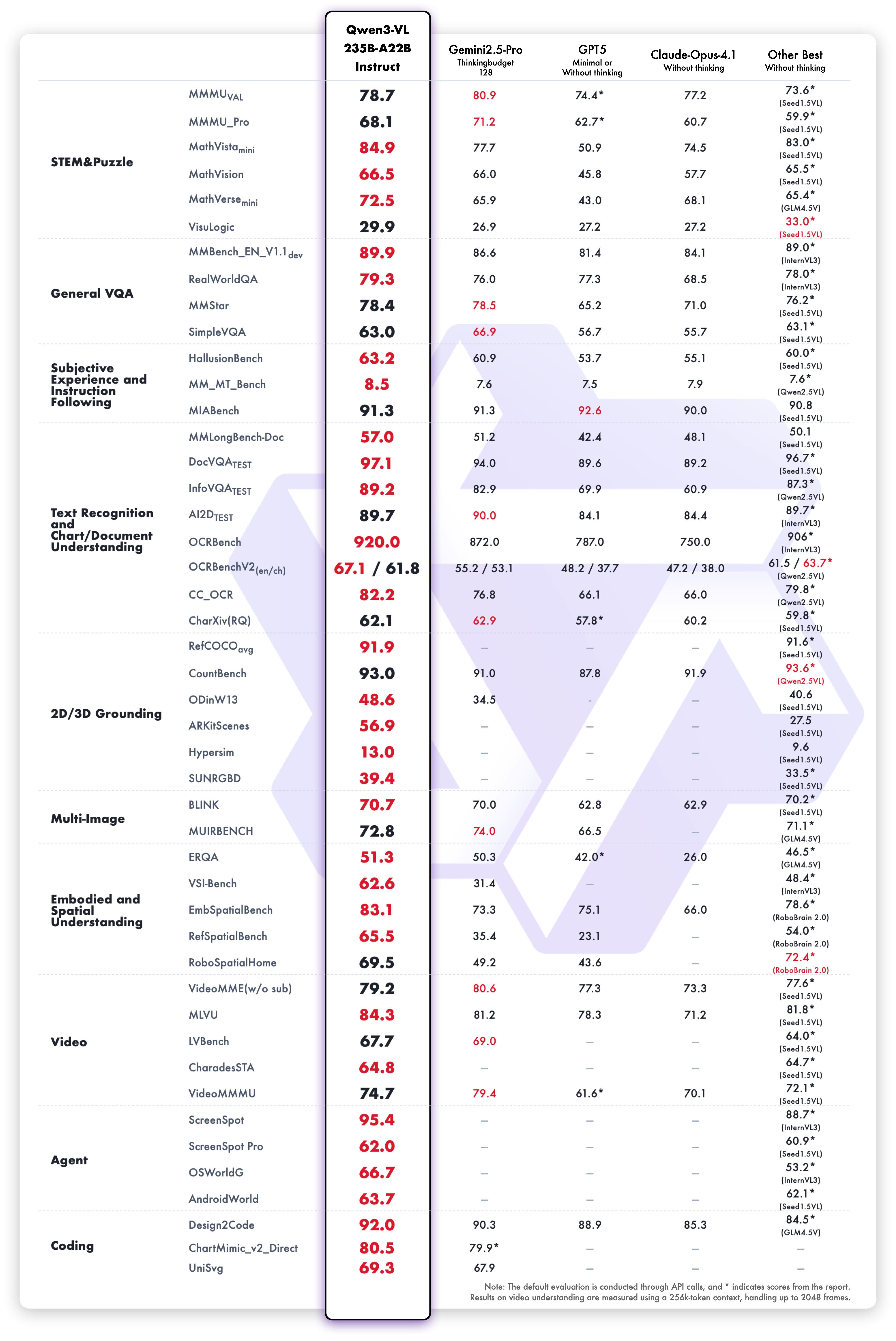
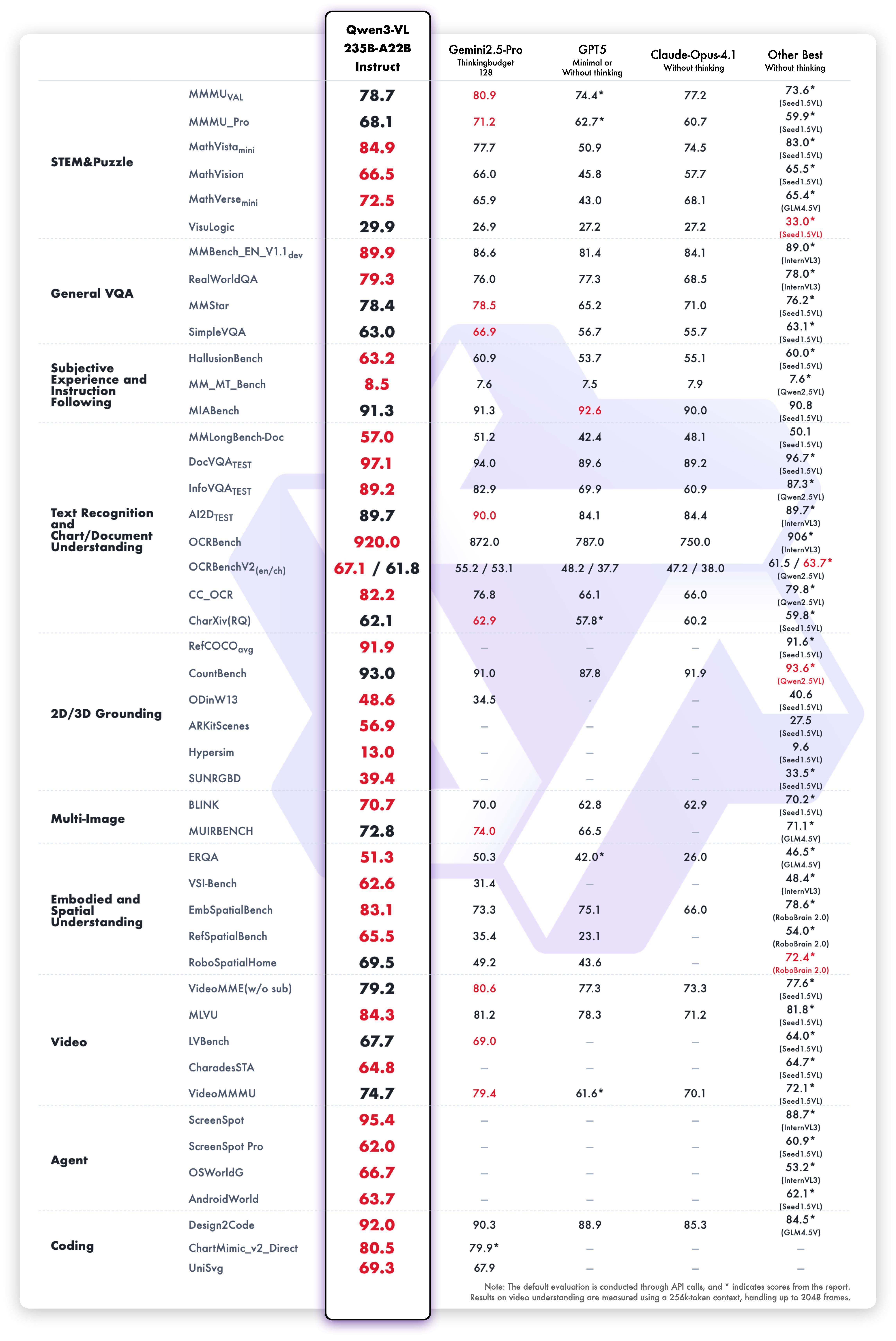
Qwen3-VL-235B-A22 Instruct测评分数
本次开源的是旗舰版Qwen3-VL-235B-A22B,有开源指令(Instruct)模型和推理(Thinking)模型两大版本。Qwen3-VL展现了在复杂视觉任务中的强大泛化能力与综合性能,在逻辑谜题、通用视觉问答、多语言文本识别与图表文档解析、二维与三维目标定位、具身与空间感知、视频理解等32项具体测评中,指令版Qwen3-VL超越了Gemini2.5-Pro 和 GPT5等闭源模型,同时刷新了开源多模态模型的最佳成绩。推理版Qwen3-VL多模态思考能力显著增强,在 MathVision、MMMU、MathVista 等权威评测中达到领先水平。
Qwen3-VL拥有极强的视觉智能体和视觉Coding能力,几乎刷新所有相关评测的最佳性能。Qwen3-VL 不仅能看懂图片,还能像人一样操作手机和电脑,自动完成许多日常任务,例如打开应用、点击按钮、填写信息等,实现智能化的交互与自动化操作。输入一张图片,Qwen3-VL可自行调用Agent工具放大图片细节,通过更仔细的观察分析,推理出更好的答案;看到一张设计图,Qwen3-VL 就能生成Draw.io/HTML/CSS/JS 代码,“所见即所得”地完成视觉编程,真正推动大模型从“识别”迈向“推理与执行”。
Qwen3-VL可支持扩展百万tokens上下文,视频理解时长扩展到2小时以上。这意味着,无论是几百页的技术文档、整本教材,还是长达数小时的会议录像或教学视频,都能完整输入、全程记忆、精准检索。Qwen3-VL还能根据时间戳精确定位“什么时候发生了什么”,比如“第15分钟穿红衣服的人做了什么”“球从哪个方向飞入画面”等,都能准确回答。
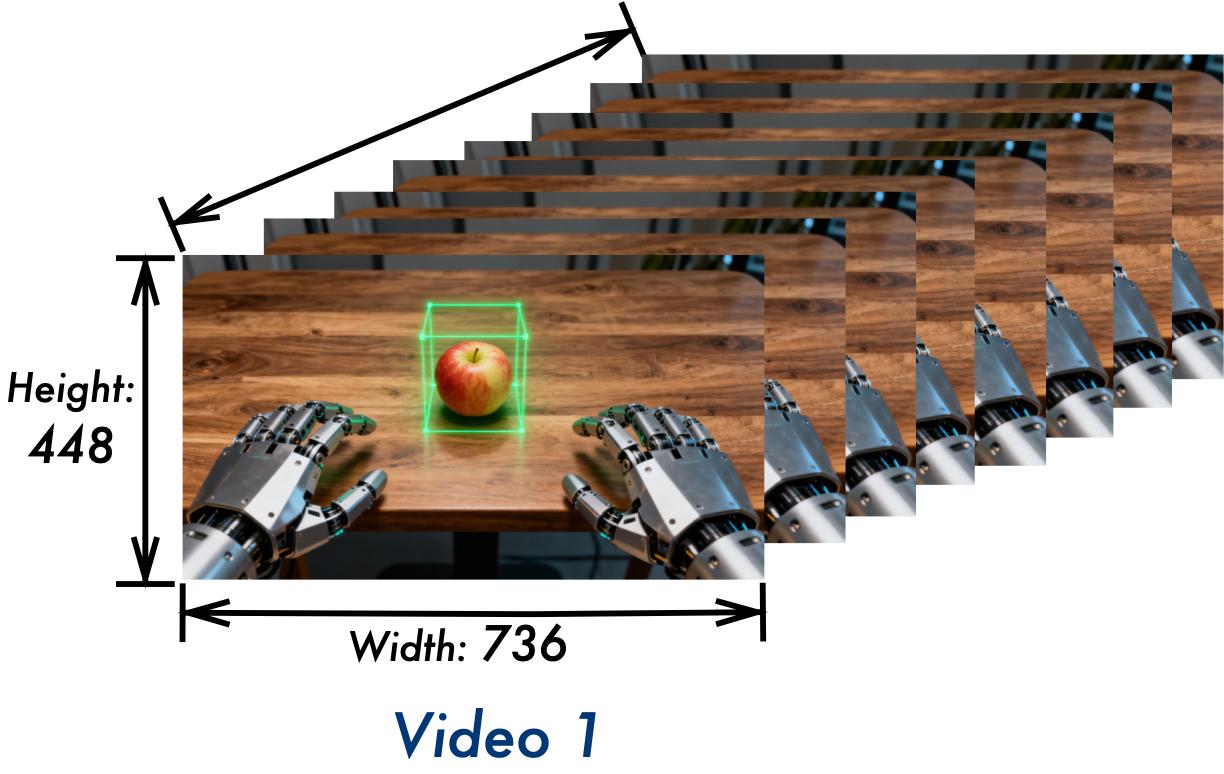
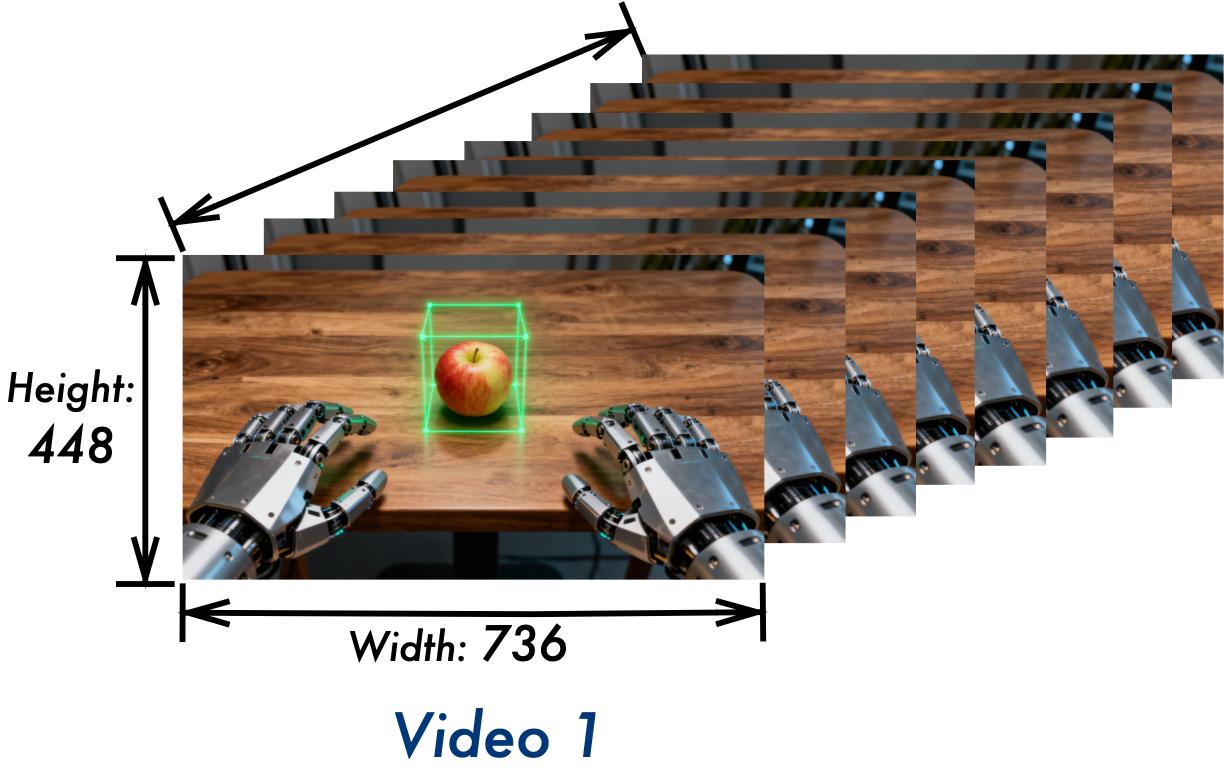
Qwen3-VL的3D检测能力增强,未来可协助机器人等具身智能判断物体的方位。
大模型的空间理解能力是实现具身智能的基础,Qwen3-VL 专门增强了3D检测(grounding)能力,可以更好地感知空间。当前,机器人想要轻松抓住桌上的一个苹果,并不容易。凭借Qwen3-VL强大的3D检测能力,未来可让机器人更好地判断物体方位、视角变化和遮挡关系,从而准确判断苹果的位置与自身距离,实现精准抓取。
据了解,千问视觉理解模型已实现广泛落地,比如国家天文台联合阿里云发布的全球首个太阳大模型“金乌”,正是基于 Qwen-VL 等模型以超过90万张太阳卫星图像为样本完成微调训练。未来,Qwen3-VL模型还将开源更多尺寸版本。即日起,用户可在通义千问QwenChat上免费体验Qwen3-VL,也可通过阿里云百炼平台调用API服务。